














JustDone AI 检测测评 2026:它准吗?莎士比亚被判 74% AI(附 JustDone vs Turnitin)
JustDone AI 检测到底准不准?我把莎士比亚原文丢进去,它判 74% AI;同一段文字在 GPTZero 那里是 Human 100%。这篇 2026 完整测评:准确性实测、误报率、JustDone vs Turnitin、以及你到底能不能根据它的分数做提交决定。
如果你被 JustDone 的 AI 检测分数吓到了,或者正在搜"JustDone AI 检测准不准"——这篇文章给你一个非常简单的常识测试。
我把一段莎士比亚原文(公版文本,确定是人写的,比现代 AI 早了几百年)粘贴进 JustDone 的 AI Detector。结果:
- JustDone 给出 74% "AI content"(截图见下)
- 页面同时强推 "Humanize my Text" 按钮,承诺"pass all major AI detectors"
- 还暗示结果被 Originality.ai / Scribbr / GPTZero "double checked"
同一段文字,我拿去 GPTZero 直接验证,GPTZero 给的结论是 Human 100%。
也就是说,至少在这次测试里,JustDone 给了一个明显的误报。而且它关于"其他检测工具也认同"的表述,你一交叉验证就站不住脚了。
说明:AI 检测工具会不断更新。这篇文章讨论的是一个可以复现的常识测试,以及它暴露出来的激励问题,不是在说某个平台"永远"就是这样。
JustDone AI 检测到底准不准?直接回答
不够准——至少不能靠它来做提交决定。 在我们的测试里,JustDone 把莎士比亚原文判成 74% AI——那是一段比现代语言模型早了约四百年的文本。同一天,GPTZero 对同一段文字给出的是 Human 100%。一个连莎士比亚都判错、却还在界面上写着"其他平台也认同"的检测器,它对你论文的判定只能当作"比较弱的信号",不能当判决。
JustDone 有没有用? 当作"这段会不会太像 AI 写的"的第二意见,勉强可以——任何检测器都能提示你去看某一段。但 JustDone 的百分比不是一个通过/不通过的数字,也不能告诉你学校的 Turnitin 报告会是什么样。如果你学校用的是 Turnitin,那才是真正决定你分数的系统。完整对比见我们的 AI 检测工具对比指南。
为什么"莎士比亚测试"是个好用的照妖镜
AI 检测器做的本质上是概率判断——它们用模型来猜"这段文字更像 AI 还是更像人"。
所以如果你想做一个快速的 sanity check,最有效的办法不是找一段"你觉得像人写的文字",而是找一段在时间上不可能由 AI 写出来的文本。莎士比亚,通过 Project Gutenberg 获取的公版全集。2019 年之前发表的学术论文。早期出版的经典文学。这些文本比 GPT 和大语言模型早了几十年甚至几百年。
一个靠谱的检测器应该毫不犹豫地把这些文本识别为人类写作。如果它连莎士比亚都判成 74% AI——那不是什么小技术故障,而是一个很响的信号,说明底层的东西出了问题。
JustDone 的结果:74% AI,然后引导你去买"人化工具"
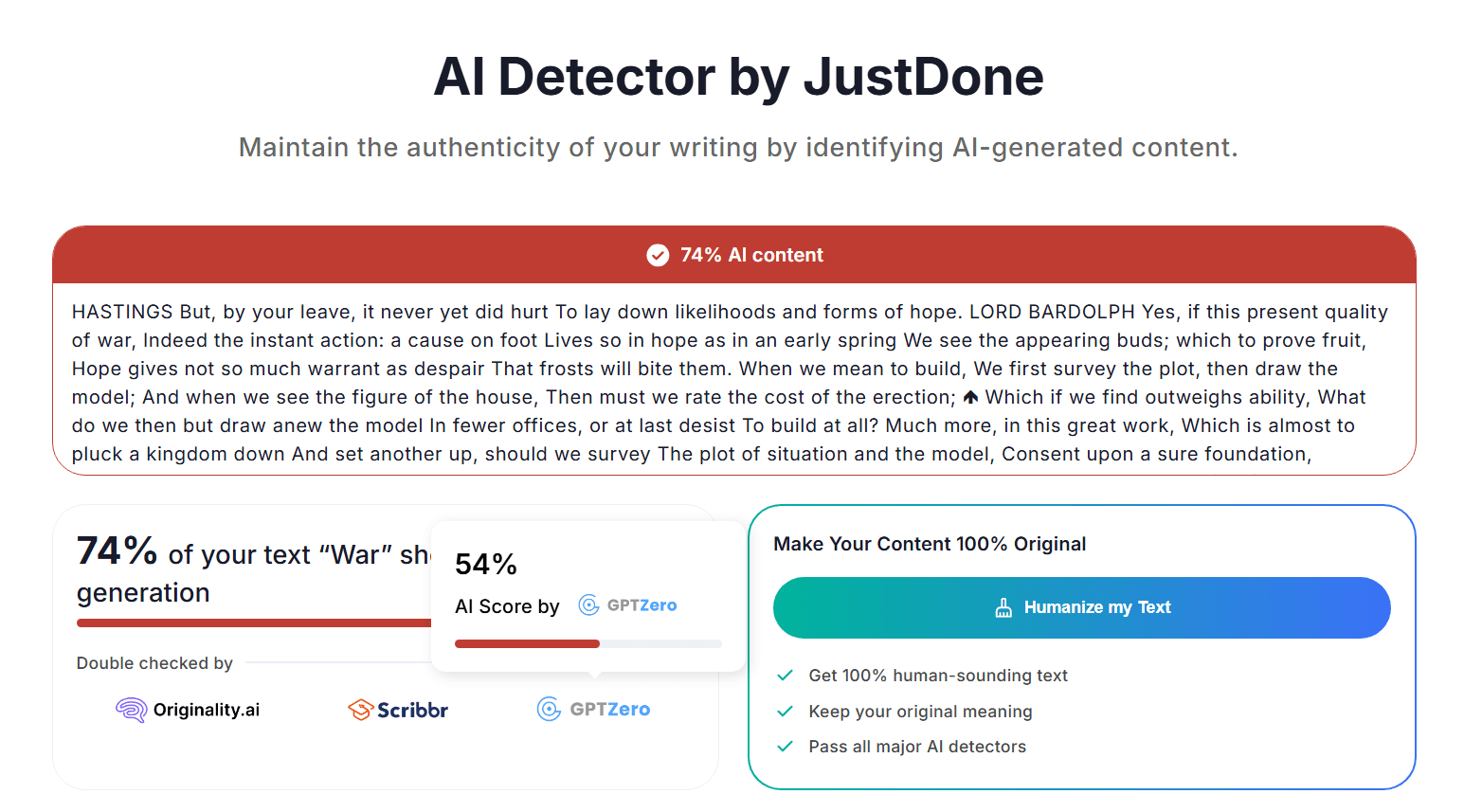 截图:JustDone AI Detector 把莎士比亚原文标成 74% "AI content",并在右侧推 "Humanize my Text"。
截图:JustDone AI Detector 把莎士比亚原文标成 74% "AI content",并在右侧推 "Humanize my Text"。
就算你不懂算法,光看页面设计就能感受到它想引导你做什么:先来一个大红条高分(制造焦虑),然后告诉你"保持原意、100% human-sounding、通过主流检测"(提供希望),最后把"Humanize"按钮放在最显眼的位置(促成付费)。
这已经不只是技术问题了——这是个商业模式问题。当"检测结果"直接服务于"卖改写工具",你很难指望这个平台把"降低误报"当首要任务。事实上,误报对它的生意是有好处的:分数越吓人,点击"Humanize"的人就越多。
"其他检测工具也认同"?我们自己验证了一下
JustDone 页面上写着 "Double checked by …",给人一种"别的平台也背书了这个判定"的感觉。
但实际情况是这样的:我把同一段文字直接放到 GPTZero——
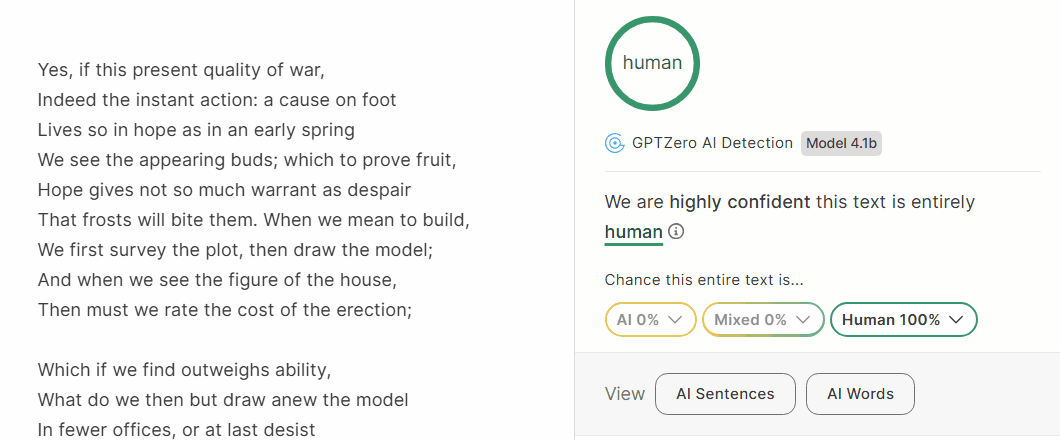 截图:GPTZero(Model 4.1b)给同一段文字判定为 Human 100%。
截图:GPTZero(Model 4.1b)给同一段文字判定为 Human 100%。
| 平台 | 同一段莎士比亚文本的结果 | 意味着什么 |
|---|---|---|
| JustDone | 74% AI content | 明显误报 |
| GPTZero | Human 100% | JustDone 的高分不是共识 |
我不会说 GPTZero 永远都对——没有工具永远对。但问题在于:如果一个检测器暗示"其他平台也认同",可你一交叉验证就发现对不上,那它的可信度就要大打折扣了。
这对学生意味着什么
当 AI 检测分数如此不靠谱的时候,学生容易被推向两个极端:
虚假安全感——在某个检测器上看到低分就当万事大吉,即使你学校用的是完全不同的工具。
虚假恐慌——看到高分就急着去跑"人化工具"甚至"洗稿",反而可能弄出新问题。
实际上,学校关心的通常不是某个网站的颜色进度条。他们关心的是你的作业是否符合政策、你能否解释你的写作过程(有提纲、有草稿、有来源、有引用、有版本记录)、以及你有没有用违规的改写或代写服务。
相关阅读:
越是"先标红再卖药",越不值得信
所有检测器都可能误报——包括 Turnitin。这是正常的技术局限。但"偶尔误报"和"误报方式恰好对生意有帮助",是两码事。
当一个平台同时出现这三个特征的时候,你要格外小心:在明显是人写的文本上给出高 AI 分数、页面语言暗示外部验证也认同、然后立刻把你引向自家的付费"人化/改写"工具。
这个组合——制造焦虑,然后卖解药——不只是 JustDone 在做,在消费级 AI 检测领域还挺常见的。认识到这种模式很重要。
更稳的做法
如果你的目标是降低提交风险又不搞灰色操作,方法其实很朴素:
对齐学校的系统。 如果是 Turnitin,就照着 Turnitin 来。别把精力花在你学校不用的工具上。Turnitin 官方说明。
保留可解释的写作证据链。 提纲、草稿、笔记、来源、引用、版本记录(Google Docs 或 Word Track Changes)。如果有一天有人问你"这篇是怎么写出来的",你能把过程展示出来,这比任何检测器分数都管用。
交叉验证可以做,但别迷信分数。 如果多个工具都标了同样的段落,这说明那些段落可能确实太"模板化"了。修改方向是:加具体性——课程概念、证据、例子、你自己的推理。
避免"人化/洗稿"式改写。 这些工具的效果不稳定,而且可能增加学术诚信风险。双重 lose。
如果你想在提交前做一个更贴近学校场景的预检查,我们可以提供 Turnitin AI 检测报告。
总结
莎士比亚测试简单直接,结果也说得很清楚了。JustDone 对一段几百年前的、百分百是人写的文本给出了明显的误报,同时把用户往付费"Humanize"产品上导。对学生来说,这不是一个可以用来做提交决策的工具。
把任何 AI 检测分数当信号,不是判决。你的最佳保护不是某个网站上的绿色分数——是对齐学校的系统,并且保留一套你能解释清楚的写作过程。
FAQ
JustDone vs Grammarly:用哪个更靠谱?
完全不同的东西。Grammarly 是写作辅助工具——帮你改语法、调语气、提升清晰度。JustDone 的定位更像"检测 + 人化"的转化漏斗:先用高分吓你,再把你导向付费改写。对于真正想把作业写好、写得可解释、符合学术规范的同学来说,Grammarly(搭配引用、草稿、版本记录)通常更有价值。JustDone 的百分比分数——尤其在连莎士比亚都判错的情况下——不应该影响你的提交决策。
GPTZero vs JustDone:为什么结果完全相反?
不只是"模型不同所以分数不同"这么简单。JustDone 一边把莎士比亚判成 74% AI,一边还写着 "Double checked by …",让人以为 GPTZero 等工具也认同这个结论。但我们直接去 GPTZero 复测,结果是 Human 100%。
换句话说:JustDone 不只是误报,而是在用"交叉验证/背书"的话术让你更相信它的误报。再加上页面上立刻推销自家的 AI Humanizer,这就是典型的"先制造恐慌,再卖解药"。不同检测器确实会因为模型差异产生波动,但波动解释不了"Double checked by …"这种让用户误以为第三方也认同的说法。这不是技术分歧,是诚实性问题。
Turnitin vs JustDone:学生到底该看哪个?
如果你学校用 Turnitin,那 Turnitin 就是你的现实基准。不是某个免费网页工具。Turnitin 也不完美,但它是为机构流程设计的系统,通常更注重控制误报。详细对比可以看我们的 AI 检测工具对比指南。
提交前想拿到真实的 Turnitin AI 检测报告?
消费级 AI 检测器的分数很容易互相打架,甚至出现明显误报。如果你所在院校最终看的是 Turnitin,Purply 可以在提交前提供真实的 Turnitin AI 检测报告,帮助你更有针对性地修改,减少不必要的焦虑与误判风险。
如果你在以下方面遇到困难:
- 不同平台 AI 分数相互矛盾,不知道该信谁
- 担心误报引发约谈、重交或学术诚信风险
- 需要在提交前做一次更接近学校场景的预检查
- 学校用 Turnitin,但你无法直接访问报告
我们会这样带你做:
把你的初稿或问题发过来,我们带你过一遍:
- Turnitin AI 检测报告(真实 Turnitin)
- 提交前风险点提示与修改方向建议
- 更关注清晰度与证据链的写作改进建议
- 紧急截止日期支持(可沟通加急)